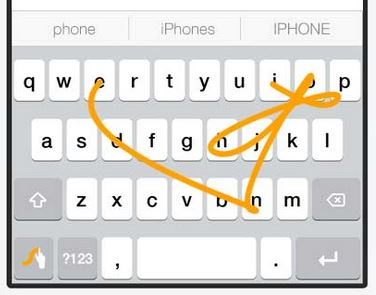
Many smart phone users had already seen and used swipe keyboard to texting in their smart phone. It comes so natural to some people to input this way. As a developer, this system is mind blowing. I could not even imagine where to begin to figure out the algorithm for recognizing messy traced line from finger swiping on keyboard, and suggest output words.

Example: this line will generate the following raw data.
I O P O J H J K O K J N B V F D E
I O P O J H J K O K J N B V F D E
System will generate a series of characters that was overlapped by traced line from start to end.
After a few weeks of researching, I kind of know how this system works.
Here are the processing steps:
Here are the processing steps:
2- Scoring raw data
1- Raw data
Scoring raw data process is tricky. The main purpose of this step is to figure out what are the characters that user want to type out of this long series of character?
The goal is the focus on these Red characters: I O P O J H J K O K J N B V F D E . Each one of these red character will be assigned high value (range from 0 to 1) may be 0.8 and the remaining gray character may be assigned 0.02. I will explain how this score value will effect the ranking result in the next section "Searching from Dictionary and Ranking the suggested words".
After taking a closer look at the line and raw data, I recognized three key patterns:
2.1- Start & End of the line: This is the most obvious thing to point out, right? Generally, this pattern will be assigned score 1 (highest score). So we got I and E
The goal is the focus on these Red characters: I O P O J H J K O K J N B V F D E . Each one of these red character will be assigned high value (range from 0 to 1) may be 0.8 and the remaining gray character may be assigned 0.02. I will explain how this score value will effect the ranking result in the next section "Searching from Dictionary and Ranking the suggested words".
After taking a closer look at the line and raw data, I recognized three key patterns:
2.1- Start & End of the line: This is the most obvious thing to point out, right? Generally, this pattern will be assigned score 1 (highest score). So we got I and E

2.2- U Turn: The peek of the U turn is most likely the character that user want to input. The peek character is determined by two same characters in both sides. Such as: O P O; J H J; K O K . Generally, this pattern will be assigned score 0.8
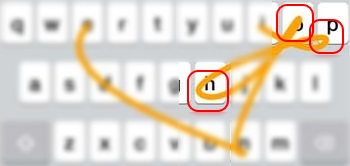
2.3- L Turn: Similar to U turn, but L turn happen when traced line cross over multiple row. Take a look at this partial string J N B . J is in row # 2 then traced line cross over to row # 3 to N B . So N is the peek of L turn. This pattern is the most trickiest and it is entirely depend on your keyboard layout. Generally, this pattern will be assigned score 0.5
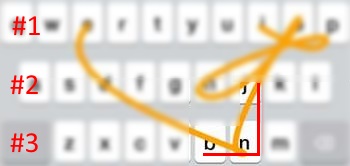
Some special exception you might need to consider, for example in this case: V F D . V is in row # 3 and traced line cross over to row # 2 F D. Why F is not considered as the peek of L turn. Well, base on the layout V is not position directly under F, that's why it is not consider as the L turn pattern.

However, I cannot dictate what is the only right way to go for. You can decide what work best for you. That mean you need to do a lot of experiment and see the result by yourself.
You can introduce your own pattern and assign its score to improve accuracy in Searching and Ranking process. I would be more than happy to hear and learn from you.
You can introduce your own pattern and assign its score to improve accuracy in Searching and Ranking process. I would be more than happy to hear and learn from you.
3- Searching from Dictionary and Ranking
This is the final step, and there are many ways to do it. One simple solution is to filter only the high score or characters that are recognized by pattern. Then searching for "Similar" word from dictionary. In this case: IPHONE, it happen to be the real word by itself.
What if the high score characters is IPHONFE? Which we got extra character F that system recognized from previous step as L turn. In built-in string comparison function, it can only compare to find out whether two string is the same string or not. At best string comparison can ignore case sensitive.
What if the high score characters is IPHONFE? Which we got extra character F that system recognized from previous step as L turn. In built-in string comparison function, it can only compare to find out whether two string is the same string or not. At best string comparison can ignore case sensitive.
To find similarity degree of two string, we can use an algorithm called Levenshtein distance.
Basically, the algorithms return number that indicate the difference between two string. So the lower the number the more similar those two strings are.
Example: The Levenshtein distance between "Kitten" and "Sitting" is 3, since the following three edits change one into the other:
Basically, the algorithms return number that indicate the difference between two string. So the lower the number the more similar those two strings are.
Example: The Levenshtein distance between "Kitten" and "Sitting" is 3, since the following three edits change one into the other:
- Kitten → Sitten (substitution of "S" for "K")
- Sitten → Sittin (substitution of "i" for "e")
- Sittin → Sitting (insertion of "g" at the end).
Last step is Ranking process: Imagine you might found 2 similar words from dictionary given by IPHONE, they are:
- iPhone
- Phone

In my experimentation, it seam that the longest matched word most likely will has higher score. Sometime, that is what user expect as well. But it is not always the case.
Try to limit your suggested words as few as possible. Because there is no much screen real estate to display many of them. The good number is 3 suggested words.
I am now looking for a way to improve. If you have any feedback or opinions, I am happy to hear about it.
Thank you very much for spending your valuable time reading my blog.
Try to limit your suggested words as few as possible. Because there is no much screen real estate to display many of them. The good number is 3 suggested words.
I am now looking for a way to improve. If you have any feedback or opinions, I am happy to hear about it.
Thank you very much for spending your valuable time reading my blog.
 RSS Feed
RSS Feed
